
SQL Server Indexing Basics – 7 Lessons Learned
SQL Server indexing basics are critical to query and server performance. Resources, like CPU and disk, are affected by the indexes that you have, or the ones you’re missing.
In the StackOverflow2013 database we’re going to look at Badges and users. Specifically, I want to start by seeing what badges a user has and when that user received them. Some badges, because of the type of badge it is, can be awarded more than once.
SELECT TOP 5000* FROM [StackOverflow2013].[dbo].[Badges] SELECT TOP 50* FROM StackOverflow2013.dbo.Users;
The UserId in the Badges table corresponds to the ID in the Users table. So, we can join them like this:
SELECT U.Id ,U.DisplayName AS DisplayName, B.[name] AS BadgeName, B.[Date] FROM dbo.Badges AS B INNER JOIN dbo.Users AS U ON B.UserId = U.Id
That’s going to return a lot of rows so I’ve looked in the Users table for some interesting displayname values and have selected to look at displayname ‘kobra’ for this demo. Notice I’ve added an ORDER BY so we can see the displayname and the date on which the badge was awarded.
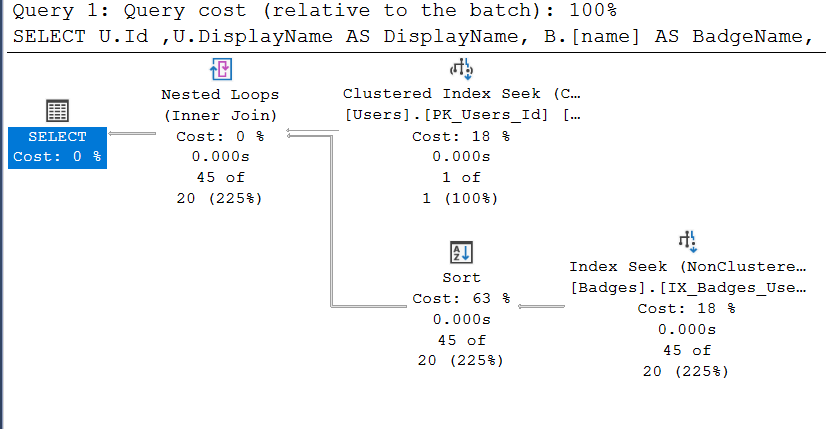
SET STATISTICS IO, TIME ON; --What are the badges that a particular person has and when were they awarded? SELECT U.Id ,U.DisplayName AS DisplayName, B.[name] AS BadgeName, B.[Date] FROM dbo.Badges AS B INNER JOIN dbo.Users AS U ON B.UserId = U.Id WHERE U.ID = 165778 --kobra ORDER BY U.Id, B.[Name], B.[Date];
This takes about 1 second to run and I’ve also enabled the capture of the actual execution plan by using CTRL + M in SSMS.
Starting at the top, the first thing that happens is SQL Server does a seek on the primary key of the Users table to look for ID value 165778.
Next, It does a scan of the badges table on the clustered primary key to find the badge name and the date, using the predicate in the WHERE clause from the query. It thinks there will be 25 rows that match. It finds 45.
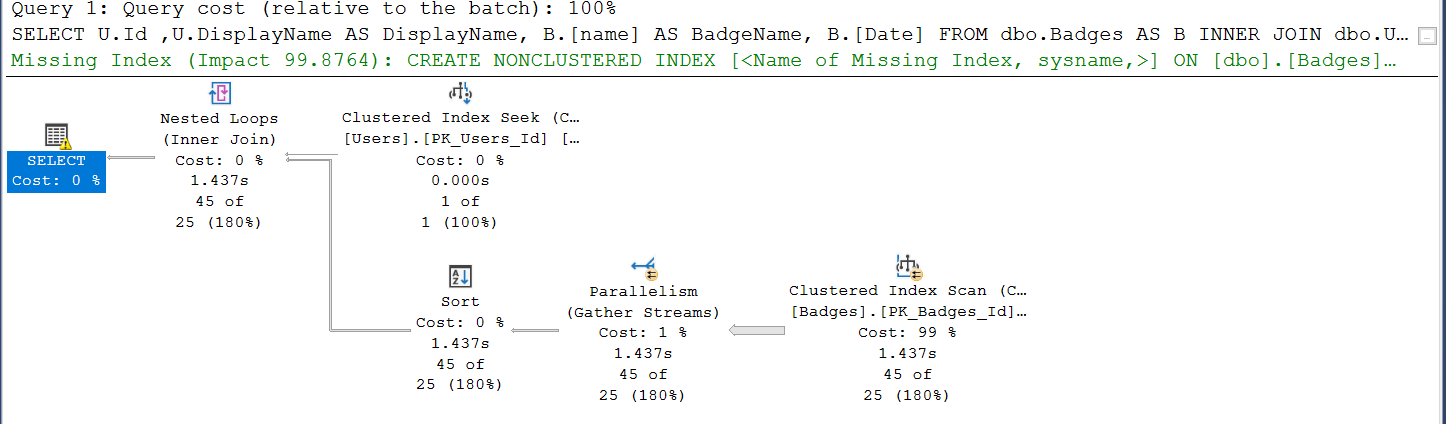
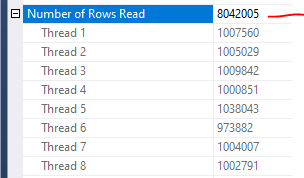
Notice the parallelism getting the data for the Badges table. When I left click that index scan operator for Badges and then hit F4 on the keyboard to show operator properties, I can scroll down the window that appears in the bottom right and find the total number of rows read. When that is expanded, we can see the number of rows read by each cpu thread.
Continuing to the left, we see that gather streams work involved in the parallelism to bring together the data gathered by the different cpu threads and then a Sort operator to order the data by name and then date. This sort is present because of the ORDER BY and the lack of any indexes other than the Primary Key for the Badges table.
Because the number of rows to be joined between the two tables is roughly even, SQL Server chooses a Nested Loops join and then finally the SELECT is done. There is an exclamation point on the SELECT operator because of an excessive memory grant.
Observations from the plan and the SET STATISTICS IO, TIME ON:
- Parallelism to scan the clustered index on the Badges table
- Sort operator to sort by Name and Date
- Logical reads around 50,000 on the Badges table
- Logical reads are 3 on the Users table
- 1 Worktable
- SQL Server has a missing index recommendation for us
/* Missing Index Details from LeeMarkumLLC-Indexing_ExecutionPlans.sql - SKOLARLEE-PC\SQL2019.StackOverflow2013 (skolarlee-PC\skolarlee (69)) The Query Processor estimates that implementing the following index could improve the query cost by 99.8764%. USE [StackOverflow2013] GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Badges] ([UserId]) GO */
Now, if you just roll with the index recommendation, SQL Server will use that, but it’s not really a full solution. SQL Server will do an index seek on the new index, but still has to go do key lookups on the clustered primary key to get the Name and Date values. Now it joins them together and still does a sort. Notice though that the parallelism is gone.
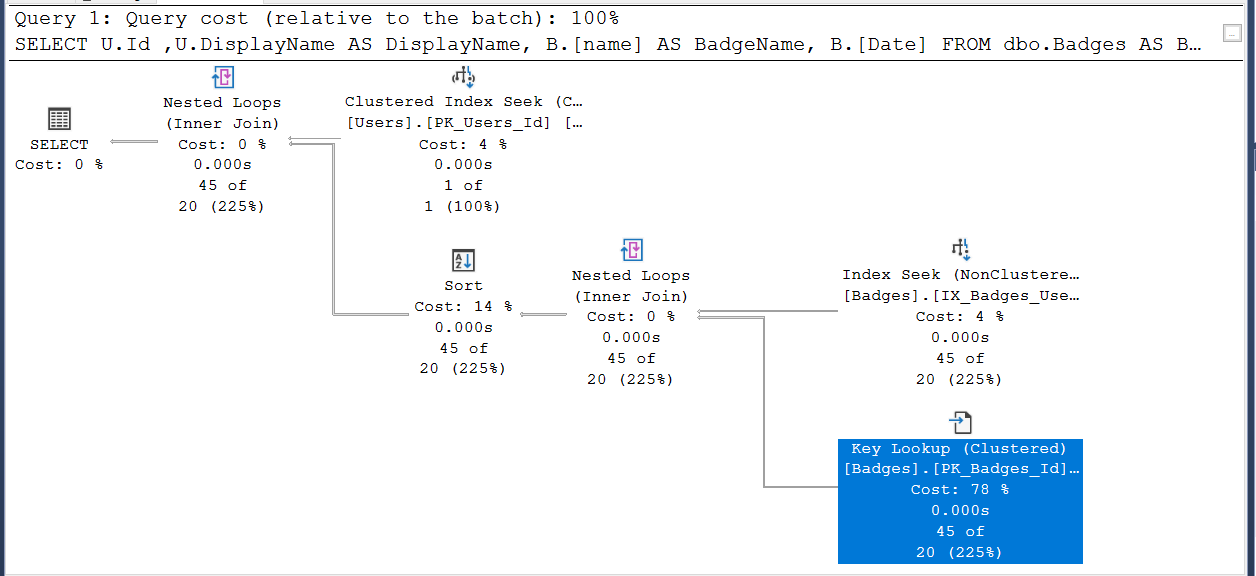
- No parallelism.
- Still doing a sort.
- 138 logical reads on the badges table, instead of 50,000.
- Still have a worktable.
Name and Date are in the SELECT list and the ORDER BY. What if you went with this index instead?
CREATE NONCLUSTERED INDEX IX_Badges_UserID_Name_Date ON StackOverflow2013.dbo.Badges ([UserId],[Name],[Date] );
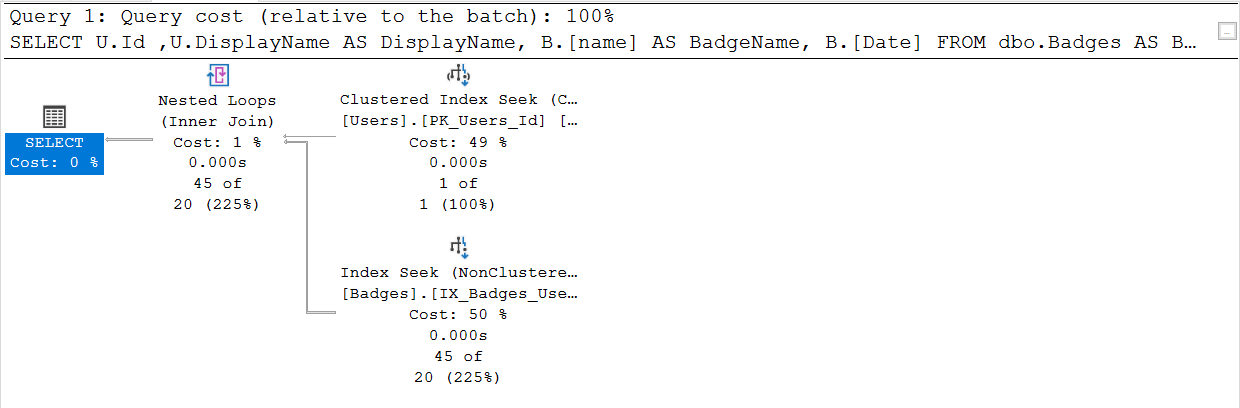
- No parallelism
- Index Seek on new index.
- Four Logical reads on the badges table, instead of 50,000 or even 138.
- No sort operator because the columns in the index are in the order of the ORDER BY in the query.
- No worktable to do the sort.
- Elapsed time is 101 milliseconds
What if we drop that index we just made and make this one instead? Will that change anything?
CREATE NONCLUSTERED INDEX IX_Badges_UserID_Date_Name ON StackOverflow2013.dbo.Badges ([UserId],[Date],[Name] );
We get two seeks, but the sort is back. Why? Well, look at that last index again. What did we do? We goofed and listed the columns as Date then Name. This order no longer matches the ORDER BY in the query. So, now the sort operator is back. The order of the key columns matters for index performance.
So, what have we learned?
- Your database likely needs more than just a clustered primary key for an index.
- Blindly trusting missing index recommendations won’t get you to a happy place. They aren’t enough by themselves. You have to look at the rest of the query, and your existing indexes.
- The order of the columns in the key of the index matters for eliminating expensive sorts which can put pressure on Tempdb on your disks.
- Indexing can seriously reduce the amount of logical reads SQL Server has to do to complete a query.
- When additional indexes are made, parallelism can be eliminated. This reduces CPU usage by eliminating large table scans to retrieve data.
- Reducing parallelism and those large table scans, is also going to reduce IO on your disks. If you’re in the cloud, you’re likely paying for CPU and disk IO usage. Want to save some money? Be sure you’re indexing is good.
- You can left click an execution plan operator and then press F4 to get more details about what that operator is doing.
Next Steps To Take
- Check out my Services page and set up a call with me via my Calendly so we can discuss the problems you’re having in your environment and how I can help.
- Experiment with simple queries and indexes in the downloadable StackOverflow2013 database to learn SQL Server indexing basics for yourself
- If you have questions or comments, leave me a comment on this post, or message me on LinkedIn or Twitter
[…] Lee Markum has seven lessons for us: […]